Im Editor können Sie Text oder komplette Segmente zu Zwecken des Qualitätsmanagements markieren. So können Sie beispielsweise Segmente mit stilistischen oder grammatikalischen Fehlern markieren und anschließend statistische Analysen anhand dieser Daten durchführen. Die Fehlerkategorien können Sie im Bedienfeld des Segmenteditors zuweisen.
Übersicht
Für die Qualitätssicherung stehen Ihnen im Editor vier Panels zur Verfügung:
- „QS Statistik“, das dazu dient, nach bestimmten QS-Kategorien zu filtern.
- Der Bereich „Segment-Metadaten“, der aufgeteilt ist in
- „Terminologie“: Hier werden Treffer mit der TermCollection angezeigt.
- „Falsch erkannte Fehler“: Hierüber können Sie falsche Positive etc. steuern;
- „Manuelle QS (ganzes Segment)“: Prüft auf Segmentebene auf Qualitätsprobleme;
- „Manuelle QS (im Segment)“: Prüft innerhalb eines Segments auf Qualitätsprobleme.
- „Status“: Hier kann vermerkt werden, ob ein Segment nochmals überprüft werden soll.

QS Statistik
Hier sehen Sie eine Liste mit Fehlerkategorien, welche in der Qualitätssicherung überprüft und teilweise automatisch, teilweise manuell auf Segmentebene zugewiesen werden können. Sie können die Segmente anhand dieser Kategorien filtern und anzeigen lassen, indem Sie die Kategorien im Filterfeld mit Häkchen markieren. Wenn Sie eine der Hauptkategorien auswählen, werden alle Unterkategorien dieser Hauptkategorie ebenfalls ausgewählt. Dasselbe gilt für das Abwählen einer Hauptkategorie. Über die allererste Zeile „Alle Kategorien“ können alle Haupt- und Unterkategorien an- oder abgewählt werden. Fehlerkategorien, die aktuell in keinem der Segmente auftauchen, können nicht angewählt werden. Mit dem Dropdown oberhalb der Fehlerkategorien können Sie steuern, ob Sie
- alle Fehler
- nur Fehler
- nur Falsch-Positive
anzeigen lassen möchten. Sie können für die Filterung die Dropdown-Auswahl mit den angewählten Kategorien kombinieren.
| Falsch-Positive sind Stellen, die automatisch als falsch ausgewertet wurden, aber in Wahrheit keine Fehler sind, z. B. wenn im Ausgangssegment eine Zahl steht, diese aber mit einem Zahlwort übersetzt wird, würde dieses Segment mit einem Zahlen-Fehler markiert werden, da das System die Zahl im Zielsegment nicht finden kann. |
|---|---|
| Fehlerkategorien, deren Zähler auf „0“ steht, da es keine Segmente gibt, auf die diese Kategorie zutrifft, können nicht ausgewählt werden. |
| Diejenigen Kategorien, die auf Fehler verweisen, welche einen Export der Aufgabe blockieren, wie strukturelle Tag-Fehler, werden mit roter Schriftfarbe hervorgehoben. |
Segment-Metadaten
Falsch erkannte Fehler
Dieser Bereich im Bedienfeld des Segmenteditors zeigt die Fehlerkategorien an, die dem aktuell geöffneten Segment zugewiesen wurden. Die einzelnen Fehlerkategorien können hier auf "Falsch-Positiv" gesetzt werden, was bedeutet, dass die Stelle fälschlicherweise als Fehler erkannt wurde.
| Bitte beachten Sie, dass das Setzen des „Falsch-Positiv“-Häkchens sofort gespeichert wird, selbst wenn die Bearbeitung des Segments ohne Speichern abgebrochen wird. |
|---|
Manuelle QS (ganzes Segment)
Hier können Fehlerkategorien für das komplette Segment zugewiesen werden.
| Bitte beachten Sie, dass die Zuweisung von Fehlerkategorien sofort gespeichert wird, selbst wenn die Bearbeitung des Segments ohne Speichern abgebrochen wird. |
|---|---|
| Die hier angezeigten Kategorien können für jede Aufgabe einzeln über die Datei „QM-Subsegment_Issues.xml“ im Import-Zip festgelegt und entsprechend auch dort angepasst werden. |
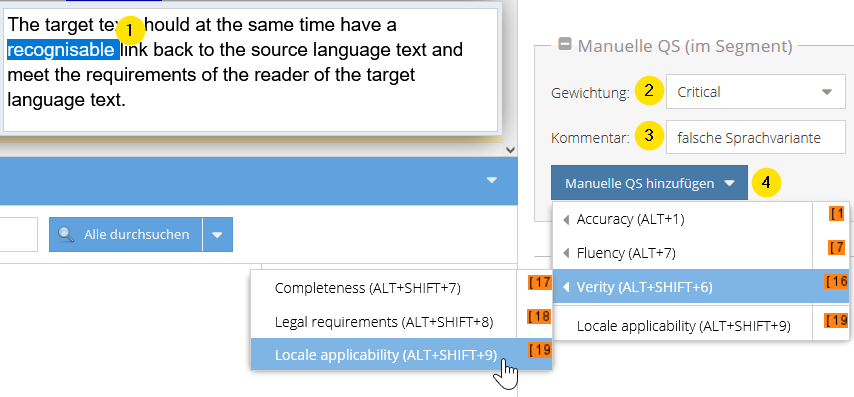
Manuelle Qualitätssicherung (im Segment)
Bei der manuellen Qualitätssicherung im Segment können Sie für ein oder mehrere Wörter innerhalb eines Segments eine Fehlerkategorie zuweisen. Dabei gehen Sie wie folgt vor:
- Betreffende Stelle im Segment markieren.
- Schweregrad des Fehlers aus dem Dropdown auswählen (optional).
- Kommentar hinzufügen (optional).
- Fehlerkategorie auswählen über das Dropdown „Manuelle QS hinzufügen“.
Das Dropdown-Menü „Manuelle QS hinzufügen“ ist mehrdimensional. Wenn Sie das Untermenü einer der Kategorien anzeigen möchten, reicht es, mit der Maus darüberzufahren. Sie können aber auch direkt eine der auf der ersten Ebene erscheinenden Fehlerkategorien zuweisen.
Die betreffende Stelle wird dann von einem orange hinterlegten Tag-Paar umgeben.
Das System merkt sich die zuletzt gewählten Fehlerkategorien und bietet sie unter den Kategorien der ersten Ebene zur direkten Auswahl an.
| Die hier angezeigten Kategorien können für jede Aufgabe einzeln über die Datei „QM-Subsegment_Issues.xml“ im Import-Zip festgelegt und entsprechend auch dort angepasst werden. |
|---|---|
| Vor der Auswahl der Fehlerkategorie kein Text markiert wird, wird auch keine Kategorie zugewiesen. |
| Die Zuweisung der Fehlerkategorien im Segment werden erst dann beibehalten, wenn das Segment gespeichert wird. |

Status
Fehlerkategorien
Hier finden Sie eine Übersicht der Fehlerkategorien und deren Bedeutung.
Einheitlichkeit
Uneinheitliche Quelle | |
| Inconsistent target |
Interne Tags
Interne Tags haben eine ungültige Struktur | |
| Interne Tags wurden hinzugefügt | |
| Interne Tags fehlen | |
| Whitespace wurde hinzugefügt | |
| Whitespace wurde entfernt |
LanguageTool
| Grammar |
| Der Text enthält einen grammatikalischen Fehler (einschließlich Fehler in der Syntax und Morphologie). |
|---|---|---|
| Spelling |
| Der Text enthält einen Rechtschreibfehler. |
| Typographical | Der Text weist typografische Fehler auf, wie z. B. fehlende/falsche Zeichensetzung, falsche Großschreibung usw. | |
| General > Characters | Das Zielsegment enthält verdrehte oder falsche Zeichen, oder solche, die in der Zielsprache nicht verwendet werden. | |
| General > Duplication | Das Zielsegment enthält mindestens ein Wort doppelt. | |
| General > Inconsistency | Der Text ist dahingehend inkonsistent, als dass er für den gleichen Begriff an unterschiedlichen Stellen unterschiedliche Benennungen verwendet (nicht mit Terminologieerkennung gekoppelt). | |
| General > Legal | Der Text ist rechtlich problematisch (z. B. bezieht er sich auf die falsche Rechtsordnung, resp. verwendet Ausdrücke und Wendungen, die nicht zum zielsprachlichen Rechtsgebiet gehörten). | |
| General > Uncategorized | Der identifizierte Fehler ist entweder nicht kategorisiert oder kann nicht kategorisiert werden (aufgrund unverständlicher Zeichenfolgen). | |
| Style > Register | Die Übersetzung ist in einem falschen Sprachregister geschrieben oder verwendet Slang oder andere Sprachvarianten, die für den Zieltext nicht angemessen sind. | |
| Style > Locale-specific content | Die Übersetzung enthält Inhalte, die nicht für die zielsprachliche Kultur oder das zielsprachliche Land gelten. | |
| Style > Locale-violation | Der Text verstößt gegen die Normen für das vorgesehene Gebietsschema. | |
| Style > General style | Der Text enthält stilistische Fehler. | |
| Style > Pattern problem | Der Text stimmt nicht mit einem Muster überein, das zulässige Inhalte definiert (oder stimmt mit einem Muster überein, das nicht zulässige Inhalte definiert). | |
| Style > Whitespace | Der Leerraum im Ausgangs- und Zielsegment stimmt nicht überein oder das Zielsegment verstößt gegen bestimmte Regeln für die Verwendung von Leerraum. | |
| Style > Terminology | Es wurde eine falsche Benennung oder eine Benennung aus dem falschen Bereich verwendet oder Benennungen werden uneinheitlich verwendet. | |
| Style > Internationalization | Es gibt ein Problem im Zusammenhang mit der Internationalisierung von Inhalten. |


Leere Segmente
| Leere Segmente |
Leerraum am Anfang/Ende
| Umbruch am Anfang | |
| Umbruch am Ende | |
| Leerzeichen nach Zeilenumbruch | |
| Geschütztes Leerzeichen am Anfang | |
| Geschütztes Leerzeichen am Ende | |
| Leerzeichen vor Zeilenumbruch | |
| Segment endet mit einem Leerzeichen gefolgt von einem Tag | |
| Tab am Anfang | |
| Tab am Ende | |
| Segment beginnt mit einem Tag gefolgt von Leerzeichen |
Längen Prüfung
| Segment ist relevant kürzer als erlaubt (mehr als 20% oder min. 100 Pixel oder min. 20 Zeichen zu kurz) | |
| Segment ist länger als erlaubt | |
| Zu viele Zeilenumbrüche im Segment | |
| Segment ist kürzer als erlaubt. |
Manuelle QS (ganzes Segment)
| Demo-QM-Fehler 1 | |
| Falsche Übersetzung | |
| Terminologieproblem | |
| Fließendes Problem | |
| Inkonsistenz |
Manuelle QS (im Segment)
| Accuracy | |
| Fluency | |
| Verity |
Nutzung von TM-Treffern
| Bearbeiteter 100% Match | |
| Unbearbeiteter Fuzzy |
Terminologie
| Verboten in Quelle | |
| Verboten in Ziel | |
| Nicht definiert in zielsprachlicher Terminologie | |
| Nicht gefunden im Ziel |
Zahlen
| Zahlen Quelle ≠ Ziel | |
| Formatänderung (Ordinalzahlen, führende Null u.ä.) | |
| Unterschiedliche Zeichen/Formatierung für Zahlen-Intervall | |
| 1000er-Trenner nicht erlaubt | |
| Dubiose Zahl aus Quelle unverändert in Ziel | |
| Alphanumerische Zeichenfolgen: Unterschiede | |
| Formatänderung (Datumsangaben u.ä.) | |
| Trenner nicht lokalisiert | |
| Formatierung 1000er-Zahl geändert | |
| Zahlwort aus Quelle als Zahl in Ziel gefunden | |
| Zahl aus Quelle als Zahlwort in Ziel gefunden. |
- Marion Gubler Tabellen vervollständigen.
- Marion Gubler SpellCheck integrieren.
- Marion Gubler Quality Assurance & Auto QA integrieren.
- Marion Gubler Manual QA inside segments / MQM Quality Assessment on Subsegment Base integrieren.
- Marion Gubler Status Assessment on Segment Base integrieren.
- Marion Gubler Terminology check integrieren.