| Table of Contents |
|---|
Versioning
Includes functions of the application up to version | 67.2.24 | ||||||||
| Current translate5 version |
|
| Change History | ||
|---|---|---|
|
Terminology recognition
Terminology recognition in the segment table is state of the art in modern translation environments — and translate5 is no exception.
It is based on the open-source licensed openTMStermTagger by Prof. Dr Klemens Waldhör and finds equivalents of the terminology imported via .tbx file using stemming, based on the Apache Lucene framework and taking into account uppercase and lowercase spelling. It can be configured, which of the two methods should be used.
| For the correct import of terminology via .tbx file, please consult the TBX file structure page. |
|---|
Terminology recognition in the editor
If a translation memory or terminology database TermCollection has been added to the task, translate5 will indicate whether a segment contains a word that is included in one of these language resources. After saving a segment, it is again checked against the terminology databaseTermCollection(s). The recognized terminology matches in the active segment are listed in the “Terminology” area “Terminology” section of the right-hand editor panel.
translate5 not only recognizes and marks terminology, but also uses a colour system in the segment table to immediately indicate whether the terminology is applied correctly or not:
| Term exists in the terminology database TermCollection and is used correctly in the target segment. |
| Term for the target language exists in the terminology database TermCollection but is not used in the target segment. |
| Source language term exists in the terminology databaseTermCollection, but without a target language equivalent. |
| An incorrect term was used that has the status forbidden “prohibited” or obsolete “obsolete” in the terminology databaseTermCollection. |










Terminology recognition in the editor panel
If a term from the terminology database TermCollection is recognized in the open segment, the entire entry is displayed in the “Terminology” section of the right-hand editor panel. The colour after behind the term corresponds to the one assigned to the TermCollection. Terms found in the current segment are printed in bold.
Classification of the terms
Each term is assigned a classification, which can be adjusted/assigned in the TermPortal:
| preferred term |
| admitted term |
| forbiddenprohibited/deprecated/not recommended/obsolete designation |
| regulatedTerm | regulated term |
| legalTerm | legal term |
| standardisedTerm | standardised term |


Display term attributes
If you hover move the cursor over the recognized terms, a tooltip appears with all attributes and — if available — images of the entry and/or the term.

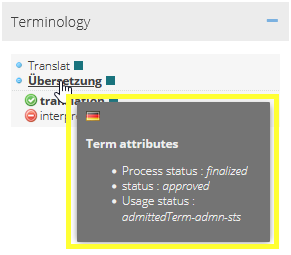
Show status
If you hover move the cursor over the symbol on the left of the term, a tooltip appears with the term’s status.


Blocking of segments due to missing target language terms
| With the help of the two plug-ins “LockSegmentsBasedOnConfing” and “NoMissingTargetTerminology“, all segments that do not contain terms underlined in red can be locked automatically. Thus, all segments that do not contain terminology problems are automatically locked. This functionality is very helpful, for example, when translate5 is used to proofread correct terminology in a translation memory. |
|---|
Spelling, grammar and style checker
| Anchor | ||||
|---|---|---|---|---|
|
The LanguageTool writing assistant built into translate5 by default provides spelling, grammar and style checking. For pure spell checking, LanguageTool builds on Hunspell, which supports a variety of languages. LanguageTool also supports a range of languages, the list of which is being continuously expanded.
Checking is carried out in the open segment, whenever there is no typing. It can also be triggered manually with the use of the F7 key. For East Asian languages, where you have to combine several keys in order to produce characters, the spell check must always be triggered manually with the F7 key.
If the target segments are already populated with text during import, or if it is pre-translated, spell checking can already take place during the import. This behaviour can be controlled via a system setting that can also be adjusted by the project manager at client and import level. It is active by default.
Spell checking in the editor
The errors found during spell checking are marked with different colours depending on the type of error:
| General errors |
| Style errors |
| Grammatical errors |
| Incorrect spelling |
| Typographical errors |







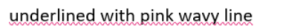


| For a comprehensive overview of the error categories that can be checked by LanguageTool, please visit the Quality assurance page. |
|---|
Apply correction suggestion
Right-click on the word to display correction suggestions. If you click on one of the suggested corrections, the error in the active segment is immediately replaced with the suggestion.
| Since LanguageTool only supports those languages by default, for which it offers grammar and style checking, languages not on that list need to be activated separatelyyou probably need to activate additional languages for spell checking. |
|---|---|
| There is a publicly available version of LanguageTool. However, the spell checker runs faster when a LanguageTool for SpellCheck-Plugin is usedwhen a when using your own local server. |