Versioning
Current translate5 version 7.35.5 Changelogs documented up to version 7.25.1
In the editor, you can mark text or complete segments for quality management purposes. For example, you can mark segments with stylistic or grammatical errors and then carry out statistical analyses using this data. You can assign the error categories in the “Quality assurance” section of the right-hand editor panel.
Types of quality assurance in translate5
translate5 distinguishes between automated quality assurance and manual quality assurance:
- During manual quality assurance, a user manually assigns an error category to a complete segment or part of it.
- Manual QA complete segment: Here, segments can be marked with various individually configured error categories.
- Manual QA in the segment: Here, parts of a segment can be commented on and assigned an error category in accordance with the Multidimensional Quality Metrics (MQM) framework or with individual error categories.
- Automatic quality assurance assigns an error category and/or comment to a complete segment or part of it.
- Automated QA complete segment covers cases such as consistency (equal source segments translated differently) or empty segments, length check or (missing) processing of 100% or fuzzy matches.
- Automated QA in the segment covers cases such as numbers differing between source and target segment, incorrect thousands separators and errors found by the spell checker.
Overview
Four editor areas are available for quality assurance:
- The left-hand editor panel “QA statistics”, where you can filter by specific manually or automatically assigned QS categories.
- The “Terminology” section of the right-hand editor panel: Terminology recognized by the TermCollection is displayed here.
- The “Quality assurance” section of the right-hand editor panel, where you can set and control the QA categories at segment and content level that can be filtered in the left-hand editor panel. This section is subdivided into:
- “False positives”: You can mark or unmark errors found by the quality assurance as false positives.
- “Manual QA (complete segment)”: Here, quality problems at segment level can be pointed out using, various predefined categories.
- “Manual QA (inside segment)”: Here, quality problems within segments can be marked manually by means of comments and severity, or using the predefined QA categories.
- “Status”: Here, a status can be set per segment, e.g. stating that a segment needs to be checked again.

QA statistics
In this section of the editor, you can see the list of error categories that are checked during quality assurance and either assigned automatically or manually at segment level. You can filter and display the segments based on these categories by ticking the categories in the filter field. If you select one of the main categories, all subcategories of this category will also be selected. The same applies to deselecting a main category. The very first line “All categories” can be used to select or deselect all main categories and their subcategories. Error categories that do not currently apply to any of the segments cannot be selected. Using the drop-down above the error categories, you can choose whether you want to:
- Show all
- Only errors
- Only ignored errors
. You can combine the drop-down selection with the selected categories for filtering.
| Ignored errors are bits of text that were flagged as false by the automated quality assurance, but are in fact not errors (false positives). This happens, for example, when there is a number in the source segment that is translated using the corresponding word. This segment would be marked with a numbers error, because the system cannot find the number in the target segment, and would therefore be an incorrectly recognized error that can be ignored. |
|---|---|
| Error categories whose counter is a “0” as there are no segments to which this category applies cannot be selected. |
| The categories that refer to errors that block the export of the task, such as structural tag errors, are marked with red font colour. |
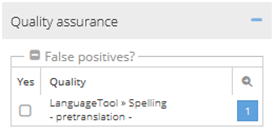
False positives
This section of the right-hand editor panel shows all error categories that have been assigned to the currently open segment. The individual error categories can be set to “ignored error” here, which means that this error category was applied incorrectly.
Marking reported errors as ignored errors individually
| Directly in the segment | In the right-hand editor panel |
|---|---|
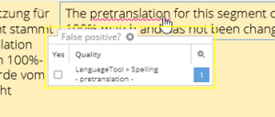
Right-click on the relevant part of the segment. A pop-up appears where you can place a tick in the “Yes” column. The reported error will now be ignored.
| In the “Quality assurance” section of the right-hand editor panel, the error categories assigned to the currently open segment are displayed. Place a tick in the “Yes” column of the list for errors that you want to ignore.
|
| Please note that setting the tick to ignore an error will be saved immediately, even if editing of the segment is cancelled without saving. |
|---|
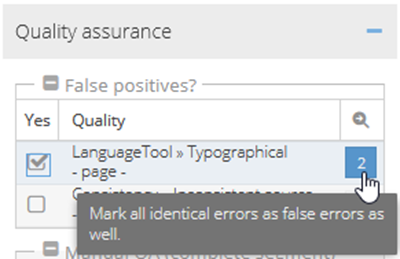
Marking all errors with same category and content as ignored errors
You can set all identical errors (i.e. having same category and content) reported by LanguageTool and terminology recognition to ignored errors.
| Directly in the segment | In the right-hand editor panel |
|---|---|
| Instead of ticking the box on the left-hand side of the menu, click on the box with the number on the right-hand side. | Click on the blue number-button in the row of the relevant category in the “Quality assurance” area of the right-hand editor panel. This can be undone by clicking on the number-button again. This number indicates the number of errors in this error category having the exact same content. Clicking on this button inverts the current status of false positivity for this and all other errors having this content and category. |
|
|

| Please note that setting the tick to ignore an error will be saved immediately, even if editing of the segment is cancelled without saving. |
|---|
Visibility of ignored errors
All those passages that were marked because of a QA error are underlined with a fine green line after the error was ignored.


Manual QA (complete segment)
Here, you can assign error categories on segment level.
| Please note that the assignment of error categories is saved immediately, even if editing of the segment is cancelled without saving. |
|---|---|
| These error categories can be defined and adjusted individually for each task in the system configuration. |
Manual QA (inside segment)
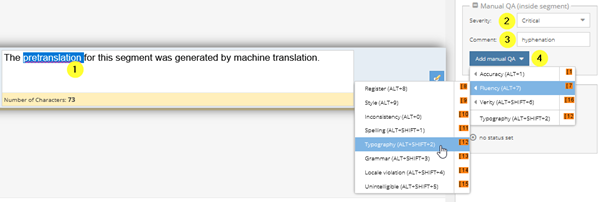
During manual quality assurance in the segment, a user can assign an error category for one or several words within a segment. To do so, proceed as follows:
- Mark the relevant bit of text in the segment.
- Select the severity of the error from the drop-down (optional).
- Add a comment (optional).
- Select an error category from the “Add manual QA” drop-down.
The “Add Manual QA” drop-down is multidimensional. If you want to display the submenu of one of the categories, just move the cursor over it. However, you can also directly assign one of the error categories appearing on the first level.
The selected segment passage is then surrounded by a pair of tags with an orange background.
The system remembers most recently used error categories and offers them for direct selection among the categories on the first drop-down level.
| The categories displayed here can be defined and adjusted individually for each task in the “QM-Subsegment_Issues.xml” file in the import zip. |
|---|---|
| If no text is marked before selecting the error category, no category will be assigned. |
| The error category assignments inside the segment are retained only when the segment is saved. |
| For more efficiency, the error categories can also be assigned via a keyboard shortcuts, see Keyboard shortcuts in the editor. |

Status
In this area, a manual quality assurance status can be assigned to segments. A status can, e.g. indicate to the reviser or second proofreader which segments should be given special attention to.
| The statuses displayed here can be defined in the configuration of your translate5 system. |
|---|
Error categories
This section gives an overview of the error categories.
Consistency
Inconsistent source | The target segment contains the same translation that was used for a deviating source segment. |
|---|---|
| Inconsistent target | The target segment has been translated differently from another target segment whose source segment content matches the current one. |
Visual representation in the segment table
If you filter the segment table according to the consistency categories, the corresponding segments are filtered, sorted and coloured:
- When filtering by “inconsistent source”, the segments are filtered and displayed alphabetically according to the content of the source;
- when filtering by “inconsistent target”, the segments are filtered and displayed alphabetically according to the contents of the target.
In addition, those segments that belong to one inconsistency group – i.e. are the same in source or target, but their source or target content is different – are coloured alternately in green and red. Within one inconsistency group, the first occurrence is coloured in a light and all subsequent occurrences in a darker shade of the same colour.


Internal tags
Internal tags have an incorrect structure | The order of the tags in the target segment is incorrect in one of the following ways
|
|---|---|
| Internal tags have been added | The target segment contains tags that are not present in the corresponding source segment. |
| Internal tags missing | Not all tags from the source segment are present in the target segment. |
| Whitespace has been added | The target segment contains at least one additional space, tab, or line break before/after a tag compared to the source segment. It makes no difference whether the space is missing before or after the tag. |
| Whitespace has been removed | The target segment contains at least one space, tab, or line break less before/after a tag compared to the source segment. It makes no difference whether the space is missing before or after the tag. |


LanguageTool
See also Terminology, style and spell checking.
| Grammar | The text contains a grammatical error (including errors in syntax and morphology). |
|---|---|
| Spelling | The text contains a spelling mistake. |
| Typographical | The text has typographical errors, such as missing/incorrect punctuation, incorrect capitalization, etc. |
| General > Characters | The target segment contains symbols that are wrong, in the wrong order, or that are not used in the target language. |
| General > Duplication | The target segment contains at least one word twice. |
| General > Inconsistency | The text is inconsistent in that it uses different translations for the same term in different places (not coupled with terminology recognition). |
| General > Legal | The text is legally problematic (e.g. it refers to the wrong legal system, or uses expressions and phrases that are not common for the target language’s legal area). |
| General > Uncategorized | The identified error is either uncategorized or cannot be categorized (due to incomprehensible strings). |
| Style > Register | The translation is written in the wrong language register or uses slang or other language variants that are not appropriate for the target text. |
| Style > Locale-specific content | The translation contains passages that do not apply to the target language culture or country. |
| Style > Locale-violation | The text violates the standards for the intended locale. |
| Style > General style | The text contains stylistic errors. |
| Style > Pattern problem | The text does not match a pattern that defines acceptable content (or matches a pattern that defines non-acceptable content). |
| Style > Whitespace | The kind or number of white spaces in the source and target segment do not match, or the target segment violates certain rules for the use of white space. |
| Style > Terminology | A wrong term, or a term from the wrong area was used, or terminology was used inconsistently. |
| Style > Internationalization | There is a problem related to the internationalization of content. |
Empty segments
| Empty segments | There are segments that have not been translated yet. |
|---|
White Space at the beginning/end
| Line break at the beginning | The segment contains an unnecessary line break right at the beginning. |
|---|---|
| Line break at the end | The segment contains an unnecessary line break at the end. |
| Space after line break | The segment contains an unnecessary space after the line break. |
| Non-breaking space at the beginning | The segment contains a non-breaking space right at the beginning. |
| Non-breaking space at the end | The segment contains an unnecessary non-breaking space at the end. |
| Space before line break | The segment contains an unnecessary space before the line break. |
| Segment ends with a space followed by a tag | The segment contains a tag at the end that is preceded by an unnecessary space. |
| Tab at the beginning | The segment contains an unnecessary tab stop right at the beginning. |
| Tab at the end | The segment contains an unnecessary tab stop at the end. |
| Segment begins with a tag followed by a space | The segment contains a tag at the beginning that is followed by an unnecessary space. |
Length check
| Segment relevantly shorter than allowed (more than 20% shorter or at least 100 Pixel shorter or at least 20 characters shorter) | Indicates that the segment's character count is significantly below layout-dependent length specification limits. |
|---|---|
| Segment longer than allowed | The segment content exceeds the permissible length specification. |
| Segment has too many lines | The segment contains more line breaks than permitted (e.g. relevant for subtitle files). |
| Segment shorter than allowed. | The segment content falls short of the permissible length specification. |
Manual QA (complete segment)
The categories displayed here can be configured individually. The following categories are available by default:
- Demo QM error 1
- Mistranslation
- Terminology problem
- Fluency problem
- Inconsistency
Manual QA (inside segment)
These default quality categories follow the Multidimensional Quality Metric (MQM) model that is based on the LISA QA model, but structured modally, as developed and defined by QTLaunchpad. QTLaunchpad was an EU supported project by the German Research Center for Artificial Intelligence (DFKI), Dublin City University, University of Sheffield and the Athena Institute for Language and Speech Processing. The categories are as follows:
- Accuracy
- Mistranslation
- Terminology
- Omission
- Addition
- Untranslated
- Mistranslation
- Fluency
- Register
- Style
- Inconsistency
- Spelling
- Typography
- Grammar
- Locale violation
- Unintelligible
- Verity
- Completeness
- Legal requirements
- Local applicability
| The categories displayed here can be defined and adjusted individually for each task in the “QM-Subsegment_Issues.xml” file in the import zip. |
|---|
Usage of TM matches
| Edited 100% match | Indicates that a 100% match from the translation memory has been edited. |
|---|---|
| Unedited fuzzy match | Indicates that a fuzzy match from the translation memory has not been edited. |
Terminology
| Forbidden in source | Indicates that a term has been used that is flagged as forbidden for the source language. |
|---|---|
| Forbidden in target | Indicates that a term has been used that is flagged as forbidden for the target language. |
| Not defined in target terminology | Indicates that the segment contains a term that is only defined in the source language, but not yet in the target language of the corresponding TermCollection. |
| Not found in target | Indicates that there is a match with the TermCollection in the source segment, but not in the target segment. |
Standardized | Indicates that the TermCollection contains a term with usage status standardizedTerm-admn-sts that was however not used in the target segment. |
| Preferred | Indicates that the TermCollection contains a term with usage status preferred or preferredTerm-admn-sts that was however not used in the target segment. |
| Others | Indicates that the TermCollection contains a term with usage status legalTerm or regulatedTerm that was however not used in the target segment. |
| Admitted | Indicates that the TermCollection contains a term with usage status admittedTerm or admittedTerm-admn-sts that was however not used in the target segment. |
Numbers
| Numbers source ≠ target | Indicates that the numbers contained in the target segment do not match those in the source segment. |
|---|---|
| Format alteration (ordinal numbers, leading zero etc.) | Indicates that the notation or format of the numbering/ordinals in the target segment differs from the one used in the source segment. |
| Different character/formatting for number interval | Indicates that the notation or format of a number interval in the target segment differs from the one used in the source segment. |
| 1000-separator not allowed | Indicates that a thousands separator that is not permitted for the target language has been used in the target segment. |
| Dubious number from source unchanged in target | Indicates that a possibly incorrect number was detected in the source segment that was transferred to the target segment and not edited. |
| Alphanumerial character sequences: Differences | Indicates differences between the source and target segments regarding alphanumeric strings, e.g. article names that have not been transferred correctly. |
| Format alteration (date information etc.) | Indicates that the notation or format of dates in the target segment is not the same as in the source segment. |
| Separator(s) not localised | Indicates that the thousands separator was transferred from the source segment to the target segment and not edited to match the target language’s requirements. |
| Formatting of 1000s number altered | Indicates that the notation or format of the thousands numbers in the target segment differs from the one in the source segment. |
| Numeral from source found as number in target | Indicates that the source segment contains a numeral (one, two, three, etc.), for which a number (1, 2, 3, etc.) was used in the target segment. |
| Number from source found as numeral in target. | Indicates that the source segment contains a number (1, 2, 3, etc.), for which a numeral (one, two, three, etc.) was used in the target segment. |